

New Zealand: Serious Vaccine Safety Signals?
Shedding light on what the New Zealand data leak tells us

Edit, 13th December 2023: Comment added at section 2.3.1 on the anonymisation of dates carried out by Steve Kirsch.
1. Introduction
There has been something of a furore in the past week or so, over a leaked file from New Zealand containing ‘record level’ Covid vaccine information for over 4 million doses administered to New Zealand citizens between April 2021 and October 2023.
The data was leaked by Barry Young, an employee of Te Whatu Ora (Health New Zealand, the state owner and operator of the database), and publicised by Liz Gunn (alt-media journalist in New Zealand) and Steve Kirsch (US alt-media journalist, social media personality, and “vaccine sceptic”).
Since the leak was made public, Barry Young has been arrested and is apparently at risk of a 7 year custodial sentence, and Te Whatu Ora have obtained an injunction on the dissemination of the data. A prominent Twitter personality, Kevin McKernan, had various social media accounts throttled and/or disabled for sharing links to the source data. I will not share the source data, for obvious reasons.
In the social media ‘debate’ following the leak, the incident has been variously described from two extremes - as the ‘mother of all revelations’, MOAR, or as a ‘nothing burger’. As is so often the case, the entire episode has involved a lot more heat than light.
In terms of the claims made by the principal protagonists in this episode, these fall into two distinct categories:
Barry Young and Liz Gunn have focussed on specific claimed ‘issues’ which they say are revealed in the data, e.g. “bad batches” and “bad vaccinators/sites”.
Steve Kirsch has focused on “time series cohort analysis” to look for signals in the data set as a whole.
It’s a shame that mixed messages were given out during the somewhat chaotic revelation of this data - this has contributed significantly to all the controversy, but such is generally the nature of these events.
In the wider scheme of things, ‘proving’ or ‘debunking’ point 1 is relatively easy. Point 2 is rather more complicated from a data analysis perspective, especially given the specific characteristics of the leaked data.
We pride ourselves on this platform in viewing issues from a different perspective than most - based on a rational, genuinely scientific approach. So I have looked at both areas in some detail. This article is my take on the saga so far.
In summary, I believe that there is a significant safety signal in the data, but to understand the complete picture, you will need to have patience and read on.
2. The Correct Way to “Analyse Data”
2.1 Understanding the Requirements
If you are responsible for building a database of any kind, the first thing you need to do is understand the “business” or “user” requirements - why are you building this database and how (do you think) will it be used?
If you are subsequently responsible for analysing the data collected, and/or reporting on it, you need to understand the objectives of those who built it, and then how it has actually been used since initial implementation.
When the data was first leaked, few if any of those who examined it appeared to have much idea of these basic points. On his own Substack page, Steve Kirsch includes a rebuttal of some of the criticisms he has received, including the following points:
There are 12M doses in New Zealand. The data drop is only for the “Pay per dose” (PPD) program in NZ which is 4M of the 12M records. Whether you got PPD or not is pretty random.
What cohort does this PPD programme cover? Answer: it’s completely random. It is not age biased or biased to any demographic. If you can prove I’m wrong, show me your data.
We can perhaps infer from this that the database was built to administer a PPD system, but (other than what has been claimed by the ‘whistle blower’ himself) this is a bit speculative since we don’t know that it doesn’t also contain the other 8M doses not part of that scheme. We also have no real evidence that the data is either “pretty” or “completely” random.
One example of the kind of question that these issue highlights is this: Why does the database include information about deaths (date of death)? If the purpose is indeed to administer a PPD system, it’s puzzling, but if it has a wider purpose - especially if the actual source data includes the other 8M dose records for New Zealand, then safety monitoring could be a function of the system.
Equally, the death dates in the leaked file could have been added from a different source completely than the rest of the data - either appended to the source database, e.g. for the express purpose of a newly identified need to investigate a safety signal, or by the ‘whistle blower’ himself during the extraction process.
Depending on the answer(s) to these questions, we can have no idea how complete the death data is in the leaked file - which renders any “analysis” of mortality rates open to some degree of uncertainty.
The problem is that we just don’t know; everything is speculation to some degree. If Te Whatu Ora had any sense, they would issue their own press release explaining the data and calmly refuting any unsubstantiated “conspiracy theories”. That they haven’t done so, instead gaining an injunction to “censor” the data, speaks volumes as to their professionalism and their mentality. They are perhaps more interested in the virtue-signalling re-naming of their agency into ‘authentic’ indigenous language than in transparently serving the tax-paying citizens of New Zealand.
We could - and most amateur “data analysts” should - stop here, since this issue of understanding the requirements and real world use is such a major one. However, if we recognise this pitfall, we can proceed (with caution and humility) in delving a little deeper into what the data might actually be able to tell us.
2.2 Understanding the Design
Good database design is a complex, highly skilled process with many facets.
It begins by understanding that a database contains information pertaining to separate, but linked, Sets of data - e.g. People and Vaccine Doses. Technically, these data sets have specific properties which make them special sets called ‘Relations’ - this is the foundational basis of Relational Databases, which most readers have probably heard about, but don’t worry, this will not be a technical deep dive into database theory.
When considering the business or real-world significance of these data sets, data analysts call them ‘entity types’, or ‘entities’ for short. Candidate entity types, with volumes (numbers in brackets), and connected via their main associations, are illustrated at figure 1.

Figure 1 is called a “Conceptual Data Model” or “Entity Relationship Diagram”, ERD, for the database (avoiding the confusing terminology of “Relation Relationship Diagram”!).
Identifying the relevant entities in a system is part art, part science - there are formal “data normalisation” rules which I won’t go into here, but most of it is common sense; it’s “obvious” that People and Vaccine Types are completely separate groups (sets) of information, which are best kept separated. The formal rules just help sanity check a design when there are complex options.
Is it in fact “obvious”, though, why the different entities are best managed separately? These are implemented as “tables” in a relational database, and a simple example illustrates the wisdom of breaking down the data into sets:
In the initial outbreak in December 2020, no one could possibly know how many named variants of Covid would eventually need to be recorded, or how many targeted vaccines would be developed. If detailed information about variants and vaccines is recorded with dose data, it’s repeated as many times as there are doses. If names subsequently change (as the ‘Kent’ version was re-branded ‘alpha’ for example, 4M (or 12M) records might potentially need updating.
Another benefit (especially during data analysis or management reporting) is the ability to sub-divide a particular entity by various classifications - for example to analyse data related to People by living and deceased, age cohort, gender (not included in the leaked data) and so on. Relevant sub-divisions, and their overlaps, can be illustrated on an ERD, as at figure 2, and - if necessary/convenient - created as database “views”, which can also be “nested”. For example, “Deceased Seniors” can be created as a view based on Deceased People and Seniors.
Views are essentially a kind of virtual table or, for anyone interested in relational database theory, “Named Relations” (tables being “Stored Relations”).

2.3 Understanding the Data
2.3.1 Summary
The leaked data covers an incomplete subset of (approximately 4.2 million) vaccine doses administered to a little over 2.2 million people in New Zealand between 8th April 2021 and 20th October 2023, a period of approximately 30 months or 2½ years.
Aside from the fact that this is a partial ‘pay per dose’ data set, as outlined at section 2.2, with uncertain provenance of death data, there are some key data items which are conspicuous by their absence in the extract:
Cause of death, e.g. as recorded on death certificates.
Vaccination site - especially given that Barry Young and Liz Gunn have highlighted certain sites at which they claim a vaccination mortality rate of around 30%.
In addition, there are a couple of other, relatively minor, quality issues with the data worth noting:
The ‘age’ field seems to be calculated on the basis of date of birth and the date the extract was created. This is valid for living individuals, but clearly invalid for those deceased, who may have died at any time from 8th April 2021 onwards.
There are a handful of records with a clearly nonsensical dose number - 11 in total with a dose number higher than 10, with a maximum value of 32!
Finally, in order to fully anonymise the data so as to prevent breaches of privacy through the identification of individuals, Steve Kirsch apparently altered dates in his released file by a random percentage of 20 days or so. If this was genuinely random method, applied consistently across all records, the effect of this on the entire file would have been effectively neutral, i.e. it would not affect analysis of large record sets - but it could potentially have an effect on small selections of data over short time frames.
2.3.2 Duplicate Records
Contrary to some assertions elsewhere, the main dose data contains very few “duplicates”. The necessary act of flattening out (“de-normalising”) a multi-dimensional relational database table structure, into a single, two-dimensional, spreadsheet of Doses (not People) gives the illusion of duplication. In fact, there are just 47 duplicate Dose records in the 4+ million row spreadsheet.
The issue arises when unqualified or inexperienced “data analysts” (including Steve Kirsch?) misinterpret what they are dealing with. This data cannot be effectively analysed in spreadsheet form, or by simply copying the spreadsheet into a single de-normalised database table.
2.3.3 Vaccine Batches
The ambiguity over what “batch_id” means in the Steve Kirsch spreadsheet is perhaps the greatest source of confusion, giving rise to the potential for misinterpreting batch statistics, especially mortality rates.
In database management, the use of “ID” (identity) usually infers a unique identifier for an entity instance, e.g. you would not expect to people to be assigned the same Person ID. But Batch ID’s have been re-used for different vaccine types. In the most extreme case, for example, 114 is re-used 8 times, as listed below:
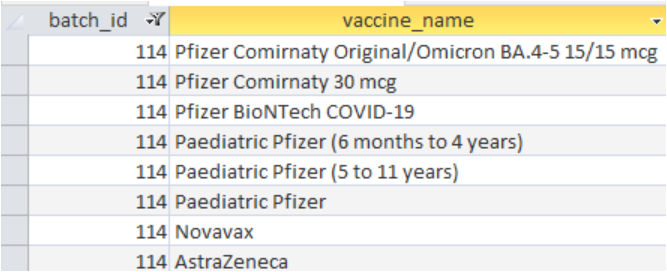
Without a proper understanding of what these batches really are, based on the documented business requirements and design criteria for the source database, as well as an understanding of real-world operation of the database since implementation, any “safety analysis” of individual batches is open to doubt.
2.3.4 Statistical Analysis v. Data Analysis
Many individual “sceptics” have done sterling work over the last four years in the area of statistical analysis - the science of looking at large data sets, averages, variations, dealing with known confounders (e.g. age standardisation, gender, ethnic background, etc.), event probabilities, and so on.
Statistical analysis though - underpinned by formal mathematics - is just one aspect of broader data analysis. That involves understanding both the provenance (aka reliability) and structure (ERD’s) of data, as well as the testing of specific hypotheses -such as whether there was spike in vaccine deaths during the initial vaccine rollout in the UK, as we have previously argued.
A ‘record level’ data set can be worth its weight in gold though - assuming the requirements, provenance and structure of the data is fully understood - in two critical ways:
Testing specific hypotheses (e.g. “bad batches”). Arguments should always be expressed in a plain English narrative alongside any statistical evidence for an extraordinary event.
Preparing appropriate, ‘clean’, data sets for subsequent statistical analysis.
3. Findings
So, what is the upshot of all this - “MOAR” or “nothing burger”? Well, it’s mixed.
3.1 The Claims of Barry Young and Liz Gunn
The Infamous Batch 1
I created a database with four tables, for the bold entities at figure 1 and populated it from the leaked spreadsheet, then conducted an analysis of deaths in the cohort who received at least 1 dose from Steve Kirsch’s “bad batch 1” (which is a Pfizer BioNTech batch not affected by the issue of re-used batch_id’s described at section 2.3.3 above.
In total, 375 people eventually died after receiving batch 1, from a total number of 2,979 people who received at least 1 dose from batch 1. That’s approximately 12.6% - which intuitively sounds high, but let’s dig a little deeper.
Firstly, I looked at how many people eventually died having had 2 doses from batch 1. That was 299 out of the 375, or ≈80% (10% of the entire initial batch 1 cohort). This is interesting, given the typical 3 week gap between doses 1 and 2, and the cold storage requirements of the Pfizer BioNTech jab. Could some of these doses have been in distributed storage locations for extended periods and suffered some kind of deterioration along the way? Unknown.
Regardless, the second dose from batch 1 wasn’t necessarily the final dose many of these people received before eventually passing away, so I put together some nested queries to provide a summary analysis as at figure 4.
This lists the details of final doses received by those in the “Batch 1 Cohort” who eventually died. The first 2 columns give the batch number and dose number for the final dose after which each of the deaths in the final column occurred. The average age refers to the average of those deaths, while the average survival is the period in days between the last dose received and the date of death. For those who received a 5th dose, which would have been approximately 2 years after their 2nd dose, their total survival time from dose 1 would be up to 2½ years.
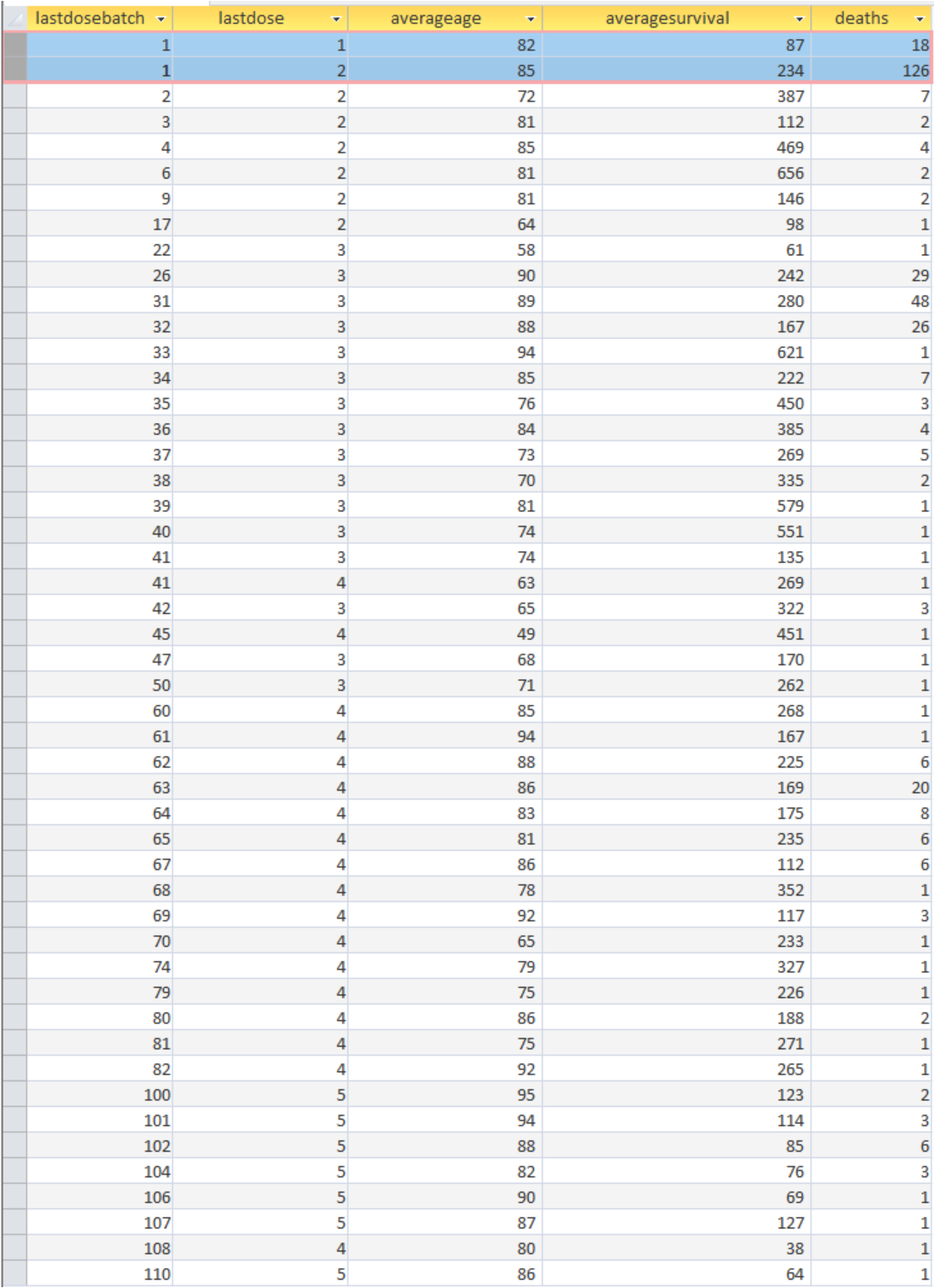
The first 2 lines relate to those whose final dose was from batch 1, i.e. they only ever had 1 or 2 doses from batch 1, never receiving a dose from any other batch. 18 of these individuals died before receiving a 2nd dose (or at least having one recorded in this partial data set), and a further 126 following a 2nd dose, with an average survival period of 234 days or 33 weeks after their last dose.
The next 6 lines detail 18 deaths in total following a second dose from a batch other than batch 1.
For the remaining lines, where the final dose received was anything between dose 3 (typically 6 months after dose 2) and dose 5 (2 years after dose 2), the death rates are not obviously remarkable given the average age of each cohort and typical life expectancy at those ages.
But what of the 2,604 people (87.4%) who have not died since having received at least one dose from batch 1?
1,108 of those individuals (42.5%) also received their 2nd dose from batch 1. This is a far smaller percentage than the 80% in the cohort who died - so could this be a safety signal relating to cold storage of doses before the second dose?
A possibility which would (at least partially) nullify this hypothesis would be a younger cohort; as well as higher average life expectancy, a younger cohort would have received their 1st (and therefore their 2nd) dose later than their elderly peers, so their 2nd dose would be more likely to have been of a later batch.
So I ran the queries. Sure enough, the average age of the “batch 1 survivor” cohort is ≈63 compared to ≈85 for the deceased.
Conclusion? “Nothing burger” - but the lack of obvious signals are inconclusive, based on incomplete/uncertain data. Further data cleansing and detailed analysis could yet identify specific issues.
Te Hopai Nursing Home Site
The video interview on rumble between Liz Gunn and Barry Young cites a death rate of over 30% for vaccines administered at Te Hopai, as well as for certain other sites. Unfortunately the Steve Hirsch main spreadsheet does not include details of vaccination sites so it is not possible to independently investigate this. My instinct is that this would be a more useful example to investigate than looking for “bad batches” based on inconclusive data.
Conclusion? Unknown - not investigated.
3.3 The Claims of Steve Kirsch
Now, finally, we get to the crunch point of the matter.
3.3.1 What (I think) Steve Kirsch Did
Critics of Steve Kirsch say that no meaningful conclusions can be inferred from the leaked data set, because:
It is incomplete - partial dose data only, for a sub-set of vaccinated New Zealand citizens.
There is no unvaccinated control group against which results for the vaccinated individuals can be compared.
Mr Kirsch counters these criticisms by asserting that a time series cohort analysis is the proper way to assess the data and that this technique is not materially affected by the lack of a control group or the incompleteness of data.
“Time series cohort analysis” sounds scarily technical - what does it mean? Simply that you look at the data for a well-defined subset of people (the ‘cohort’), over a period of time (the ‘time series’).
On balance, in terms of the general debate, I side with Mr Kirsch on this. But there are some important caveats. You need to choose and define your ‘cohort’ carefully, and I am not sure Mr Kirsch has done that - at least not in a way that is transparent to me.
Figure 5 is a cropped snapshot of a Steve Kirsch slide. The table of figures seems to reveal some key points about his specific execution of a time series cohort analysis,
Firstly, the person days average 28.9 million for each week. This implies a cohort of ≈4.1 million people. But there are only 2.2 million people in the database - has Mr Kirsch conflated people and doses (of which there are 4.2 million) in his analysis?
Secondly, and more importantly in my opinion, it is critical to recognise any selected cohort is not ‘static’ in the leaked data set. There are no unvaccinated people in the data, which implies that either:
People were only added to the source database when their first PPD dose was registered, or
People pre-existed in the source database, but the ‘whistle blower’ extract only contained records (and death dates) for people with at least one recorded dose.
Either way, the result is the same, in terms of understanding how a population cohort developed in the database over time. Today, there is data on 2.2 million people and 4.2 million doses but, a week after it went live, there would have been just a handful of records for the people vaccinated in that first week. We have no visibility for that week of anyone not in that handful of people, so any deaths in that week need to be considered in the context of the cohort size as it was at that time.
This, I think, is probably why Mr Kirsch actually seems to be looking at mortality rates per shot (as revealed in the titles of his charts). I don’t believe this is a meaningful approach, but determining a valid cohort of people for each point in his time series, in order to conduct a valid analysis, is a complex challenge.
3.3.1 What I Did
I attempted to take the spirit of what Mr Kirsch has argued - that a time series cohort analysis is valid in looking for signals from this data set - and implement the approach in what I believe is a more robust way.
Disclaimer: What I did involves numerous complex steps, with consequent potential for mistakes. It is possible that I did indeed make specific mistakes in the execution of my analysis, but I have checked and double-checked as best I can. Short of never publishing my results - so that others can attempt to re-produce or debunk them - my only option is to publish, and invite sanity checking / constructive criticism from others.
First, I chose a cohort - “eighty-somethings” - and a time period - the remainder of 2021 from when the first PPD doses were recorded up until Christmas Eve 2021.
This gave me a good sample size - of people, doses and deaths - and a time period in which I could consider the overall background to the situation in New Zealand. Crucially, due to the strict isolation and lockdown conditions in New Zealand, there was no significant incidence of Covid during this period.

Next I built my cohort by adding people to it on specific dates based on what the data was telling me. Firstly I looked at every person with ‘age’ between 80 and 90 and added them to my cohort as of the date on which they received dose one. This gave me a cohort with a growing number of people during my selected time period.
But not every 80-90 year old in the data set had a dose 1 record. So I then added everyone receiving dose 2 with no dose 1 recorded. Then I added those receiving dose 3 with no record of dose 1 or dose 2. This ensured that every ‘relevant’ eighty-something was included in my cohort for every date on which I compared deaths in that cohort to the actual cohort size. There were an insignificant number (literally a handful, which I ignored) of dose 4 shots administered to the eighty-something cohort before Christmas 2021.
I recognise that this method is not perfect (there is no ‘perfect’ method given the nature of the vaccine rollout and the limitations of this data set). An alternative approach, which I might have tried given more time, would be to exclude all data (cohort membership and deaths) for people who did not receive dose 1. I will leave this for others to consider.
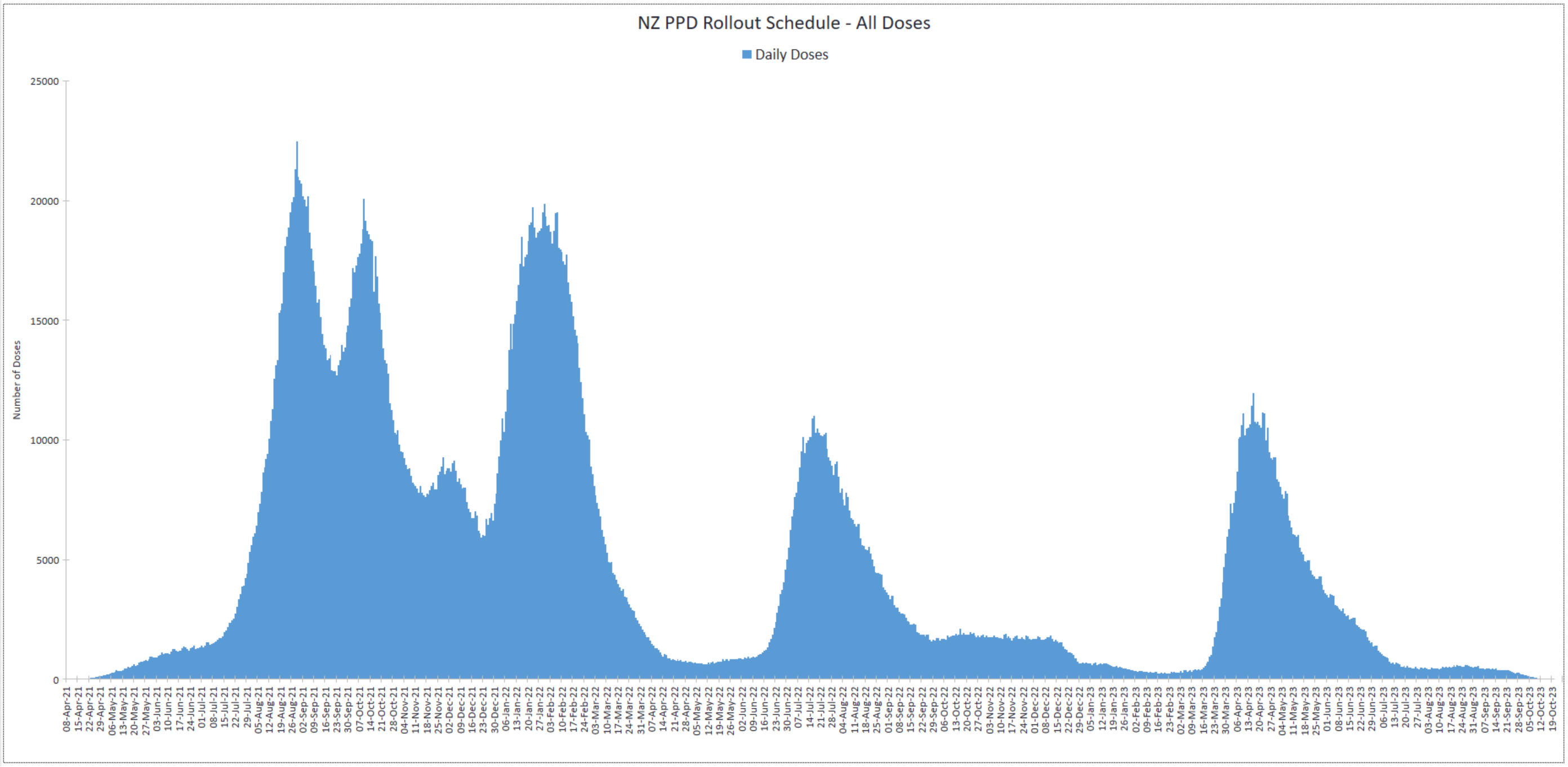
Below, I present two charts from my analysis.
The first shows the overall profile of PPD doses, for all ages, in the data set - enabling people to visualise the big picture as to when each dose was rolled out in New Zealand. Doses 1 and 2 were ramped up, approximately 3 weeks apart, in August and September 2021. Other ‘booster’ doses followed later as clearly illustrated, with a number of people in my specific cohort receiving dose 3 shots during the latter part of 2021.
In short, if we are expecting to see any significant safety signal in the data, we would expect to see it from August 2021 onwards, given that the more elderly were prioritised for the earliest shots.
So what do we see? Figure 8 shows the number of daily deaths (blue, left hand scale) in the eighty-something cohort, and the annual mortality rate (orange, right hand scale) per 100,000 people, during the selected time period. I have plotted 7 day average rates to smooth out the data and reduce noise.
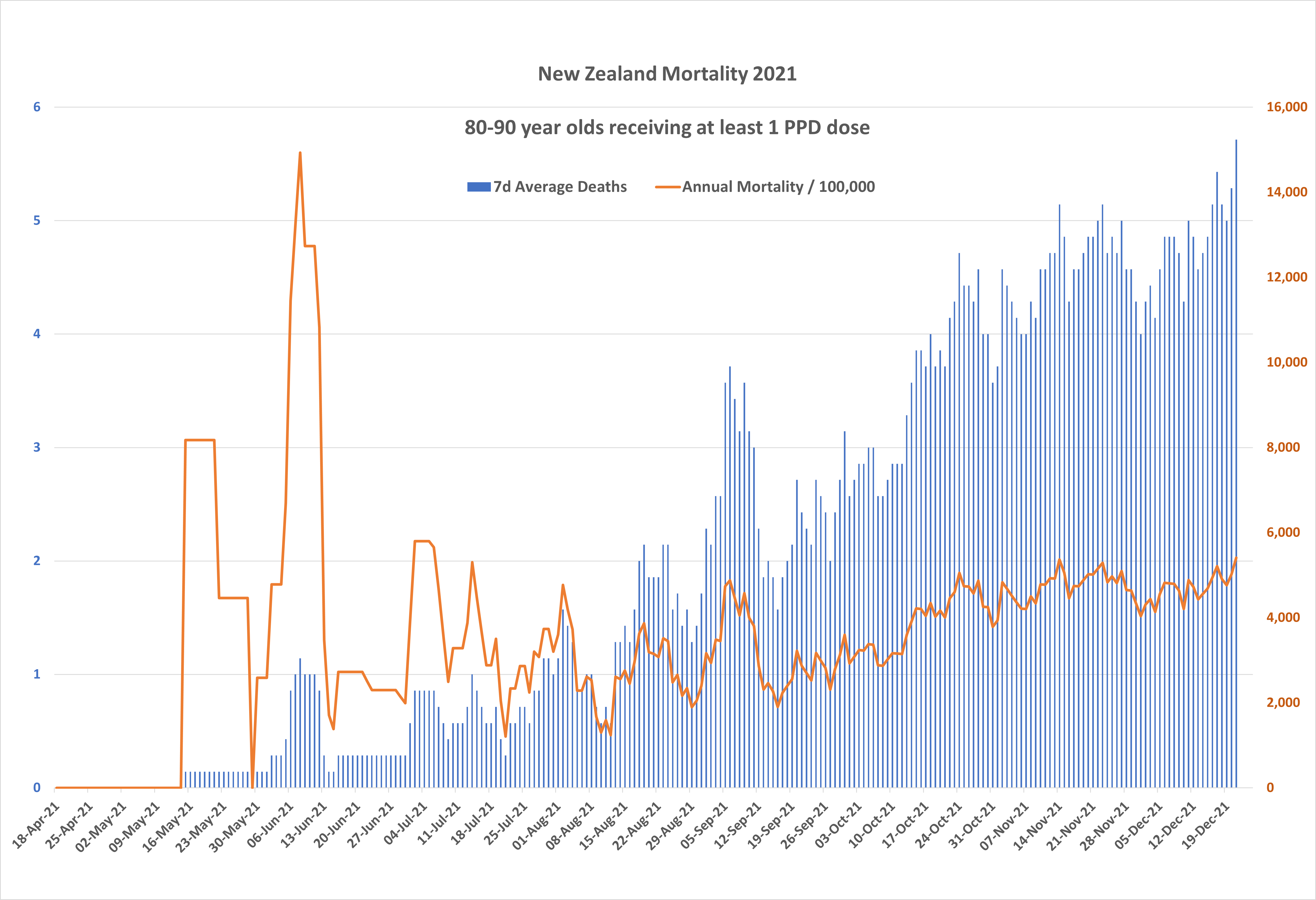
Although the first shots were recorded in early April, there is so little data available in the first month that the chart shows nothing. Daily death rates start to build, as the cohort size builds, from mid-May onwards, but the noisy mortality rate to the end of May is meaningless because the sample (the cohort size) is so small during this period - one or two deaths in a week distorts the mortality rate and makes it meaningless.
There is a small cluster of deaths in early June, 9 in total, which may be significant given the small size of the cohort at that time (2,000 on June 2nd, growing to 3,000 by June 11th. This could be an early signal of immediate post-vax mortality risk, as we have previously mooted.
The average mortality rate remains noisy during July and early August, because of the limited, gradually growing cohort size), then begins to rise steadily from mid August onwards.
Note also that the average mortality during July, while noisy, is elevated compared to the stabilised rate starting from mid August. While absolute death numbers are still small during this period (less than 1/day), this could be a further signal of immediate post-vax mortality risk.
Because our selected cohort of monitored eighty-somethings is growing continuously throughout the period, as more people are registered in the database, the prolonged steep rise in daily deaths, on its own, tells us nothing meaningful. However, the steady rise in the mortality rate from mid August onwards - if the data set is genuine and if I have not made a significant execution error in my analysis process - indicates a potential serious issue with vaccine safety.
In the absence of a control group, it is always possible that some factor other than the jabs is responsible for this increasing mortality. We can discount Covid as described above, as well as seasonality given that the selected time period runs through the southern hemisphere Spring into early Summer. However, it is possible that lockdown effects (as mooted by Igor Chudov on TwiX), additional sedation of elderly patients in care homes, or some other factor, was at play.
But we know that the vaccine rollout happened during this period, so we have demonstrated correlation - and the jabs surely have to be the prime suspect for causation.
I will not attempt to put a total number on vaccine deaths here. The total deaths in the selected eighty-something cohort during the selected period is 522, in a cohort size which averaged around 19,000 throughout the period. Readers can extrapolate their own estimates of vaccine death totals, based on the overall population of eighty-somethings and other elderly in the New Zealand population, as well as the overall period since the vaccination rollout began, but - as others have said on TwiX - there are other (generally better) ways to assess this.
For completeness, I should clarify that I did not remove any individuals from the selected cohort based on date of death. The impact of this did not merit the additional work involved in this initial analysis, but this is one of potentially several refinements that could be made to my methodology. Removing deceased cohort members would have slightly reduced the cohort size, thus tending to further increase mortality rates.
Also, as pointed out by Steve Kirsch himself, the natural aging process of a ‘fixed’ age-group naturally tends to increase death rates during any selected timeframe. Compared to the overall signal evident in the data, and the short time period I used, these effects are negligible.
Conclusion? ‘MOAR’. Serious safety signal.
4 General Conclusions
To investigate the specific impact of Covid vaccines on particular age cohorts, from particular batches, or at particular vaccination sites, statistical analysis of large aggregated data sets, while very important, is often not enough. ‘Record level’ data of the kind leaked is a useful additional tool to investigate detailed hypotheses, and to independently prepare ‘clean’ aggregated data for statistical analysis.
Investigation of such a data set can only be carried out effectively by data professionals in a database tool - excel spreadsheets are not an appropriate platform for detailed data analysis of this kind.
A complete data set of all vaccinations administered in New Zealand (or any other country), including verified and complete death data (date and recorded cause of death) as well as places of residence and vaccination sites, plus vaccinator ID, would be very helpful for independent professional analysis in the way I have attempted here - with or without comparative data for unvaccinated cohorts.
I do not believe that ‘captured’ public health and statistics agencies, including the ONS and UKHSA in the UK, are motivated (or sufficiently capable) to analyse post-vaccine adverse events or mortality rates in a professional, impartial manner.
Similarly, I do not believe that Steve Kirsch has ‘proven’ a safety signal because, although his basic approach of a time series cohort analysis is valid - for which he deserves more credit than he has received, in my opinion - there is evidence that his execution of the method is flawed. He “knows” that the method is appropriate, he “knows” that there is ample evidence from multiple sources that the shots are unsafe, and it is probable that this led him to reach his (correct) conclusion via confirmation bias rather than a valid analysis of the data.
This data set, in the form released, is not ideal - but then no data set I have ever worked with is perfect. Nevertheless, my own analysis of the data suggests that there are serious safety signals within the leaked New Zealand data.
I hope that others will now follow up on this work, to either verify or constructively disprove my conclusions. I will be more than happy to engage in further explanations or discussion of my approach, and findings, with any competent parties acting in good faith.
Brilliant work JS. Have you looked at the HMD shinyapp tool that compares rates of death from year to year? I posit that it shows a safety signal from weeks 17 to 47 of 2021, and it's the elderly who dosed up on the jab preceeding and during that time frame. The Stats NZ data, seen at their Covid-19 portal, which is the source for the HMD, shows the same.
Terry
Still no one has refuted this - and not for lack of trying. You have them running scared with this analysis. Please keep up the fight - a lot of us are cheering you on!